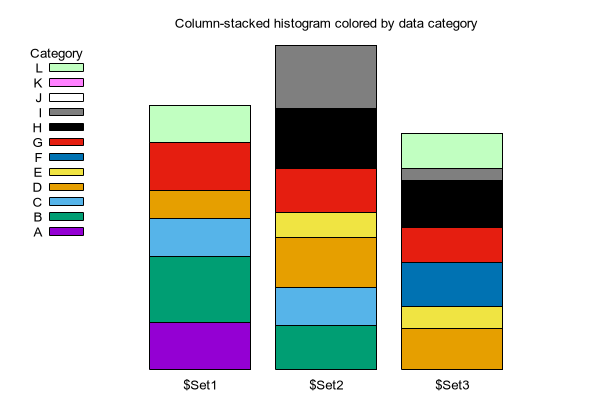
| Credits | Overview | Plotting Styles | Commands | Terminals |
|---|
The program assigns a color to each component box in a histogram automatically such that equivalent data values maintain a consistent color wherever they appear in the rows or columns of the histogram. The colors are taken from successive linetypes, starting either with the next unused linetype or an initial linetype provided in a newhistogram element.
In some cases this mechanism fails due to data sources that are not truly parallel (i.e. some files contain incomplete data). In other cases there may be additional properties of the data that could be visualized by, say, varying the intensity or saturation of their base color. As an alternative to the automatic color assignment, you can provide an explicit color value for each data value in a second using column via the linecolor variable or rgb variable mechanism. See colorspec. Depending on the layout of your data, the color category might correspond to a row header or a column header or a data column. Note that you will probably have to customize the key sample colors to match (see keyentry).
Example: Suppose file_001.dat through file_008.dat contain one column with a category identifier A, B, C, ... and a second column with a data value. Not all of the files contain a line for every category, so they are not truly parallel. The program would be wrong to assign the same color to the value from line N in each file. Instead we assign a color based on the category in column 1.
file(i) = sprintf("file_%03d.dat",i)
array Category = ["A", "B", "C", "D", "E", "F"]
color(c) = index(Category, strcol(c))
set style data histogram
plot for [i=1:8] file(i) using 2:(color(1)) linecolor variable
A more complete example including generation of a custom key is in the demo collection histogram_colors.dem